The BEHILOS Benchmark
When Unix history meets modern performance benchmarking: testing low-footprint search workhorses
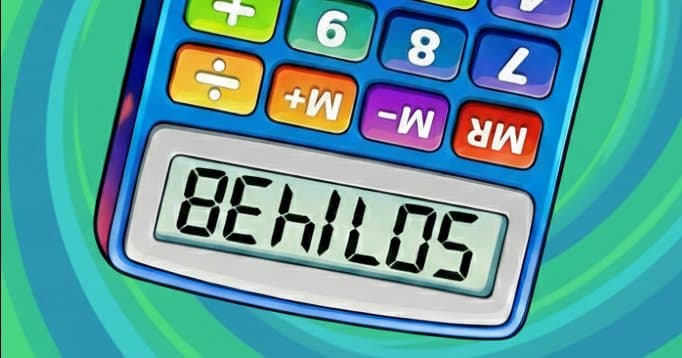
In his book Unix: A History and a Memoir, Brian Kernighan recounts his favorite grep story from the early days of Unix. Someone at Bell Labs asked whether it was possible to find English words composed only of the letters formed by an upside-down calculator. The digits on a turned calculator display, 5071438, map to the letter set BEHILOS.
Kernighan grepped the regular expression ^[behilos]*$ against the Webster’s Second International Dictionary which contained 234,936 words, and found 263 matches - including words he has never seen before.
The current Webster’s Second International Dictionary contains 236,007 words. To reproduce the results, run:
grep '^[behilos]*$' /usr/share/dict/web2
This results in 264 matches. The longest words are nine characters long: blissless and booboisie.
What started as a historical footnote quickly made me wonder: how would the old BEHILOS grep perform as a quick-and-dirty benchmark for today’s search tools?
Selected Text Search Tools for the BEHILOS Benchmark
For the BEHILOS benchmark, I selected a mix of classic and modern text search tools, covering traditional Unix utilities, AWK variants, and fast recursive searchers widely used by developers today.
grep – the classic Unix tool and historical baseline for text searching.
rg (ripgrep) – a modern, extremely fast recursive searcher optimized for large codebases.
gawk – the GNU AWK implementation, feature-rich and widely used for text processing.
mawk – a lightweight, efficient AWK variant with minimal memory footprint.
nawk – the traditional New AWK, preserving historical behavior for legacy scripts.
ag (The Silver Searcher) – a fast recursive searcher often replacing ack.
pt (The Platinum Searcher) – a newer, recursive grep alternative with multithreading support.
ack – a Perl-based source tree searcher, maintained and optimized for code patterns.
ugrep – a feature-rich, modern grep clone with extended regex support and performance tuning.
sift – a recursive search tool for large directories, optimized for developer workflows.
Benchmarking Methodology
To evaluate the performance of the search engines, the benchmarking focused on two critical metrics, runtime and peak memory usage, which together represent the total resource footprint. Resource tracking was performed using cgmemtime, an ideal tool for this purpose as it captures peak memory consumption for the process group.
The benchmarking process was automated via benchgab.awk (version 2026.02.10.), my custom runner that handles warmups, multiple test runs, and calculates statistical metrics as well as normalized parameters for comparative analysis. Each benchmark sequence included one initial warmup run followed by 100 recorded runs.
The following table summarizes the evaluated search engines, their versions, and the exact commands used for the BEHILOS grep.
Name Version Command
---- ------- -------
grep 3.12 grep '^[behilos]*$' /usr/share/dict/web2
ripgrep 15.1.0 rg '^[behilos]*$' /usr/share/dict/web2
gawk 5.3.2 gawk '/^[behilos]*$/' /usr/share/dict/web2
mawk 1.3.4 mawk '/^[behilos]*$/' /usr/share/dict/web2
nawk 20251225 nawk '/^[behilos]*$/' /usr/share/dict/web2
ag 2.2.0 ag -s '^[behilos]*$' /usr/share/dict/web2
pt 2.2.0 pt -e '^[behilos]*$' /usr/share/dict/web2
ack 3.9.0 ack '^[behilos]*$' /usr/share/dict/web2
ugrep 7.5.0 ugrep '^[behilos]*$' /usr/share/dict/web2
sift 0.9.1 sift '^[behilos]*$' /usr/share/dict/web2
Tests were conducted on an Arch Linux workstation powered by a Ryzen 5900x CPU, using the Alacritty terminal within a dwm session.
Results
The statistical summary was computed by the script, deriving the mean, standard deviation, median, minimum, and maximum from this 100-run sample for both runtime and peak memory usage.
Jitter (Jtr%) was calculated for both runtime and peak memory usage as abs((mean − median) / median) × 100%, quantifying run-to-run variability. For low-footprint commands, even minor scheduling effects or transient memory spikes can noticeably influence averages, making jitter a useful indicator of measurement stability.
--- Statistical Summary of BEHILOS Benchmarks ---
cmd Runtime [s] Peak Memory [MB]
mean ± sdev min median max Jtr% mean ± sdev min median max Jtr%
gawk 0.0220 ± 0.0008 0.0204 0.0219 0.0251 0.5 0.75 ± 0.16 0.48 0.74 1.00 1.0
ugrep 0.0087 ± 0.0005 0.0076 0.0086 0.0102 1.1 1.64 ± 0.14 1.44 1.60 2.03 2.3
ack 0.0880 ± 0.0027 0.0838 0.0874 0.1003 0.7 6.49 ± 0.26 6.12 6.39 7.19 1.6
sift 0.0402 ± 0.0021 0.0370 0.0398 0.0489 1.1 13.32 ± 2.12 9.98 13.11 20.46 1.7
mawk 0.0089 ± 0.0005 0.0078 0.0088 0.0109 1.0 0.59 ± 0.14 0.48 0.54 1.25 8.9
ag 0.0139 ± 0.0008 0.0119 0.0138 0.0167 0.5 2.22 ± 0.45 1.31 2.21 3.23 0.2
pt 0.0245 ± 0.0010 0.0227 0.0244 0.0286 0.5 8.03 ± 0.32 7.49 7.98 10.48 0.6
grep 0.0048 ± 0.0003 0.0041 0.0048 0.0068 0.3 0.71 ± 0.11 0.60 0.64 1.12 10.9
rg 0.0056 ± 0.0003 0.0048 0.0056 0.0064 1.1 1.13 ± 0.17 0.98 1.01 1.75 11.4
nawk 0.0389 ± 0.0012 0.0372 0.0387 0.0429 0.7 0.64 ± 0.16 0.48 0.73 1.05 12.4
The evaluation is based on normalized metrics:
RT: Normalized median runtime. The execution time relative to the fastest implementation (1.0 is the baseline).
PM: Normalized median group peak memory. The peak memory relative to the implementation with the lowest memory footprint (1.0 is the baseline).
d: Euclidean Distance. Measures the geometric distance from the "Ideal Point" (1,1). Lower values denote higher implementation efficiency.
F: Resource Footprint. Calculated as RT×PM. This represents the total resource footprint; lower values indicate a more efficient use of system resources to complete the same task.
The following table summarizes the overall performance of the 10 tested search engines according to the normalized BEHILOS benchmarks.
-- Normalized BEHILOS Benchmarks ---
cmd RT PM d F
gawk 4.52 1.37 3.54 6.20
ugrep 1.78 2.97 2.12 5.28
ack 18.07 11.86 20.23 214.26
sift 8.23 24.31 24.41 200.00
mawk 1.83 1.00 0.83 1.83
ag 2.85 4.11 3.62 11.73
pt 5.05 14.81 14.39 74.79
grep 1.00 1.18 0.18 1.18
rg 1.17 1.88 0.89 2.19
nawk 8.00 1.36 7.01 10.90
Discussion
The normalized BEHILOS benchmarks were evaluated using Pareto frontier analysis (as previously applied in my AWK benchmarking study). To visualize search engine performance, the normalized values were plotted in a two-dimensional coordinate system, where the x-axis represents normalized runtime (RT) and the y-axis represents normalized peak memory usage (PM).
The ideal point is located at (1, 1), representing an implementation that is simultaneously the fastest and the most memory-efficient. To improve the visibility of implementations clustered near the ideal point, a logarithmic scale was applied.

Graph: The Pareto frontier of search engines tested in the BEHILOS Benchmark, visualizing the optimal trade-off between execution speed and memory footprint.
The normalized BEHILOS results clearly separate the tested tools into distinct performance tiers when runtime and peak memory usage are considered jointly.
grep the overall winner of the BEHILOS Benchmark.
Taken together, the normalized metrics and the Pareto frontier analysis identify grep as the overall winner of the BEHILOS Benchmark. It is not only the fastest implementation (RT = 1.00) but also achieves the lowest total resource footprint, as reflected by the minimum F value (F=1.18)
grep and mawk define the Pareto frontier.
grep is the fastest implementation (RT = 1.00) while remaining very close to the minimum memory baseline (PM = 1.18). mawk, in contrast, achieves the lowest peak memory usage (PM = 1.00) with only a modest runtime penalty (RT = 1.83). Neither tool can be improved in one dimension without degrading the other, placing both on the Pareto frontier and representing the optimal trade-off envelope for this workload.
Near-frontier but dominated tools.
rg, ugrep, ag, and gawk are dominated by the frontier but remain reasonably close to it. Their normalized distance and F values indicate that they are not optimal for this specific task, yet their performance characteristics are still competitive. This reflects design choices favoring richer feature sets, broader file handling, or more general workloads rather than minimal footprint.
Clearly dominated implementations.
pt, and especially sift and ack, lie far from the Pareto frontier. Their high normalized runtime and peak memory usage result in very large F values, indicating poor efficiency for this narrowly defined benchmark. These tools incur significant overhead relative to the simplicity of the BEHILOS search.
The case of nawk.
Although nawk exhibits a low peak memory footprint (PM = 1.36), its slow runtime (RT = 8.00) places it well outside the efficient region. In addition, it showed the highest peak memory jitter among all tested tools, which negatively affected its stability metrics and overall performance profile.
Overall, the Pareto analysis highlights that tools optimized for minimalism and predictability dominate this benchmark, while more feature-heavy searchers pay a measurable cost in both runtime and memory.
Conclusion
The BEHILOS grep, despite originating as a historical anecdote from the early days of Unix, turns out to be an effective micro-benchmark. Its simplicity isolates the core costs of regex matching, process startup, and memory allocation without confounding factors such as filesystem traversal or complex I/O patterns.
This benchmark shows that, for low-footprint text searches, decades-old design principles still matter. Classic Unix tools like grep, along with lean implementations such as mawk, remain hard to beat when efficiency is the primary goal. Modern search engines deliver powerful features and excellent performance for real-world workloads, but those advantages are not free.
The BEHILOS Benchmark does not aim to crown a universal “best” search tool. Instead, it demonstrates how a minimal, well-chosen workload can expose fundamental trade-offs between speed, memory usage, and stability—and why even a small historical footnote can still teach us something meaningful about performance today.